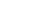
1.
Random Forests are easy to use, the only 2 parameters are the number of trees to be used and the number of variables (m) to be randomly selected from the available set of variables.
2.
If the number of cases in the training set is N, sample N cases at random with replacement, from the original data. This sample will be the training set for the growing tree.
3.
After Random Forest is built, each test data run through all decision trees, and the results are computed. We choose the class with maximum number to be the final prediction result.
4.
SVMs are a useful technique for data classification and supervised learning models with associated learning algorithms that analyze data used for classification. A SVM model is a representation of the examples as points in space
5.
The goal of SVM is to produce a model which predicts the target values of the test data given only the test data attributes. In the following four basic kernels: linear, polynomial, radial basis function and sigmoid.
6.
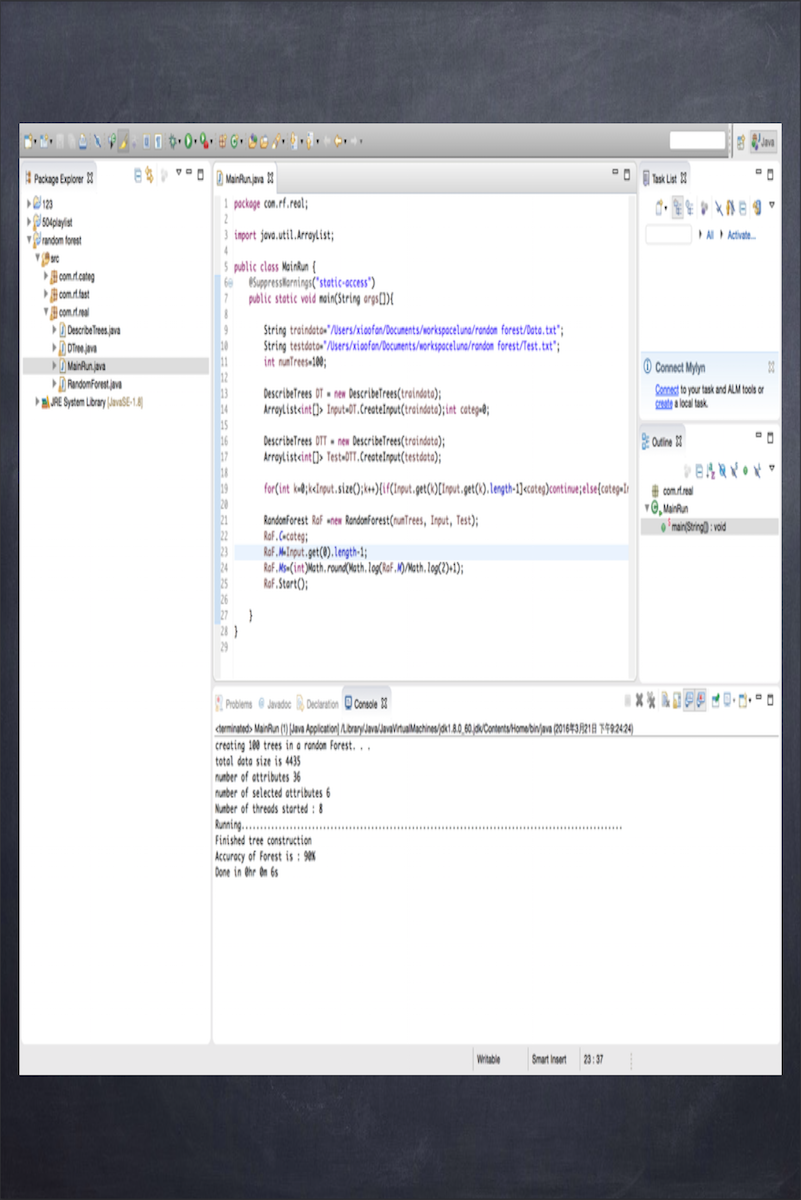
After building the algorithm and transform the data, we can get the prediction result and a precision of 68%. So the main advantage of the SVM algorithm is simple. Compared with Random Forest, it is much faster and more straight forward.







If you have any precious proposals, please feel free to contact us. We would really appreciate it if your suggestion helps us make progess ^=^.